With the rise of camera surveillance, a lot of safety concerns have seen improvement. Emergency response times have gone up, anti-social behavior has gone down, and crime has been deterred. However, it is hard for surveillance operators to determine whether a crowd is just large or dangerously large.
Crowd management in today's world is still largely manual work. In short, for a big event, a group of vigilant operators watch closely at real-time CCTV footage for any sign of over-crowding. As soon as they think a crowd gets too large, they sound the alarm and actions will be dispatched to officers who can help disperse and re-route the crowd. But how should a surveillance operator determine whether a crowd is too large?
Recently, one of our customers asked us to help them tackle this challenge for one of the biggest events in the Netherlands.
Crowd Counting AI is the digital Rain Man

In the classic 1980s movie "Rain Man," Dustin Hoffman plays the character of a severely autistic savant nicknamed the Rain Man. In one famous scene, a waitress accidentally spills a box of toothpicks onto the ground. The Rain Man sees the toothpicks and exclaims: "246!" Astonished, the Rain Man's brother (played by a young Tom Cruise) asks how many toothpicks there were in the box. Turns out there were 250 in the box and after the spill four remained.
Just imagine what disasters could have been prevented if surveillance operators had a similar ability to instantly and accurately count people in a crowd! This skill would instantly take the guesswork out of determining the danger level of any crowd.
We delved into the literature on the topic of turning machines into the Rain Man. There is a wealth of it! If you're interested in the technical details, this comprehensive overview provides an excellent summary of the latest research, models, and benchmarks in crowd counting.
Convolutional Neural Networks rule the Crowd Counting scene
One interesting finding of our research and various experiments is that convolutional neural nets, an invention from the 1980s, rain supreme when it comes to crowd counting. For the last couple of years, most of the machine learning space has been focussed on transformers, the architecture that came about in 2017 and made ChatGPT possible. But even though we ran quite a few experiments with transformers our final solution was still based on the convolutional neural nets.
What are Convolutional Neural Networks (CNNs)?
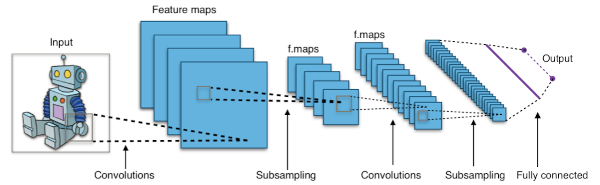
A CNN analyzes images by breaking them down into small sections, like looking at a picture through a small window and then moving that window across the entire image. This process, known as convolution, allows the network to recognize patterns, such as the shapes of faces in a crowd. A CNN performs many such convolutions in parallel and in sequence, each one with a unique sliding window that looks for particular patterns, like the corner of a mouth or the tip of a hat. A neural network stacks many such convolutions behind each other such that the tip of a hat, the corner of a mouth, and eyes are all integrated by another convolution into the pattern of a person's head.
The patterns of convolutions are learned by the CNN by training it on a large number of images. For each image of a crowd that we feed the network we also give it information on where people are located, usually by providing the exact pixel location of the middle of the head of each person in the image. A CNN eventually learns to associate patterns in the pixel data with patterns that inform it where people's heads are.
State Of the Art crowd counting with CNNs
Since the seminal paper Single-Image Crowd Counting via Multi-Column Convolutional Neural Network was published in 2016 till today in 2024, CNNs have been the dominant machine learning algorithm for crowd counting purposes.

Even though more sophisticated machine vision neural network architectures exist today, variations on CNNs still are at the top of the leaderboards. Modern machine learning architecture such as Mamba, invented in December of 2023, have temporarily extended the State Of The Art, such as VMambaCC, but convolutional neural networks have caught up with these results time and time again. CNN models such as FFNet and APGCC, just to name a few.
A recent paper actually hypothesized that Mamba isn’t well suited for vision tasks. To test their hypothesis they constructed an experimental architecture called MambaOut that takes the most innovative part out of Mamba (the SSM block) and leaves the convolutions that Mamba leverages under the hood in. They found that MambaOut outperformed plain Mamba on the task of image classification.
In short, it’s hard to beat CNNs on some tasks. CNNs have well-known limitations, of course, also known as inductive biases, but it very much seems that those limitations align perfectly with the limitations that any form of intelligence will have in counting people in image data. CNNs are extremely good at crowd counting and on modern hardware run faster than the Rain Man himself.
From count to alarm sound
Now that we can supercharge surveillance operators with the power of CNNs, how should we use this information to make sure crowds can stay safe? At what point does the operator sound the alarm?
This is where critical values come in. Each camera needs to have one for the maximum number of people it should see for a certain angle it is in. The video data of the cameras must be continuously fed into the neural network and if the critical value is exceeded, the operator should be notified that a dangerous situation is occurring. These critical values can be established either by doing the math (e.g. how many square meters are in the field of view multiplied by how many people can we have per square meter) or by baselining. An operator can establish a baseline by looking at historical or real-time footage with its associated count. If it gets busier than that time, the operator gets notified and can either extend the baseline or sound the alarm. The math can, of course, also serve as a good starting point for setting a baseline.
When placing the cameras we need to be aware of the fact that there are limitations to how well a crowd counting algorithm can perform. Given a low-resolution image of a very zoomed-out picture of a stadium full of people, one cannot reasonably imagine any form of intelligence coming up with an accurate estimate for how many people are visible. Intelligence has limitations just like physical laws have limitations. Therefore, ideally, cameras need to be placed in certain positions and kept at preset angles that make the count accurate based on how high the resolution is. A critical value should be associated with a preset angle for a given camera. Once you've got those two in place, you can rest assured that once it gets too busy, the operator will know it immediately.
The future of crowd counting
While machine vision models will continue to evolve, the most significant advancements may not come from the models themselves, but from how we apply them in real-world scenarios. They are already quite good. Helping operators establish good critical values is more useful. One may wonder, is an operator even helped by knowing the exact number of people in a scene? Or should an indicator of crowdedness be enough? Can we automatically tell whether a camera is well positioned for the purpose of crowd counting and/or provide a measure of uncertainty? There are still many ways to improve, but by leveraging the power of CNNs we've successfully upgraded our customers to the future of safety.