
Blogs
March 23, 2020
Oddity.ai Team
Oddity.ai

This blogpost offers a quick and approachable look at one of the technical deep learning problems faced at Oddity.ai and outlines how we go about solving such problems. In any deep learning application, the amount of data is an important factor for success. Gathering this data is not always an easy task. We are looking at alternative methods for increasing the size of our datasets, such as data synthesis.
These days many tech innovations are driven by deep learning. This sub-discipline of artificial intelligence is concerned with automatic learning from data and has given rise to e.g. face recognition, semi-self driving cars and a personal assistant in your pocket. However, the deep learning models require massive amounts of data for their training process. In the training process they are fine-tuned to achieve a task by presenting them many examples of the task. As the tasks we want to solve get more complex, the deep learning models get more complex and more data is required to train the model. Andrew Ng, one of the most influential figures in AI, summed it up as follows: "I think AI is akin to building a rocket ship. You need a huge engine and a lot of fuel. [..] The analogy to deep learning is that the rocket engine is the deep learning models and the fuel is the huge amounts of data [..]." Of course, with a bigger rocket, more fuel is needed.
This is a problem because 1) such large amounts of data are not always available and 2) data collection often violates the right to privacy of people. This is something that many companies struggle with when deploying deep learning research insights in practice. At Oddity.ai this issue lies close to our hearts as we are building action recognition models that can be used for violence detection on video surveillance streams. With privacy being a core value, we do not want to collect real videos of fights from live surveillance cameras. And thankfully, we are also not allowed to do so. On the other hand would more available training data lead to an even better product and by extension safer streets, as more violence would get detected.
The data we are looking for can fortunately be found elsewhere. Violence is objectively horrible in real-life but omnipresent in popular media. Mixed Martial Arts is more popular than ever, the quality of fight-scenes in Hollywood movies has never been this high and everyday kids spend hours playing Grand Theft Auto on their game console. Video footage is available for all these examples. The violent actions visible in these videos contain valuable information that we could potentially present to our violence detection model. This way it might get a better view of what violence constitutes. So why not train our model on this data?
Screenshot of a fight scene from Grand Theft Auto V.
Before we can do that, however, we need to make the visuals of these videos representative of what we expect our model to encounter in the wild. Training on data that is different than what we expect in production is an instance of transfer learning. For example, the model should not associate a box ring and two half-naked men, as visible in MMA matches, with violence. Neither should it look at the amount of stars in the top-right corner of the GTA screen as an indicator for the amount of violence to expect. Instead the punches the athletes throw at each other should be associated with violence. At Oddity.ai we expect our product, tailored for video surveillance, to encounter video footage from streets or the interior of buildings. We also expect the camera to be in a fixed position, attached to e.g. a wall or pole. In order to make the alternative violence videos ready for our existing model to train on, we should make sure that they look like the videos we expect **in production. This is a big challenge and requires extensive reworking of the video. The entire environment needs to be repainted (from a box ring to a street), the actors in the video might need different clothes (no naked torsos), maybe even different body shapes or changed lighting. How can we ever accomplish such large modifications?
It might be easier and more rewarding to go a step further than just reworking the original video. By using pose estimation techniques, we can extract human motion from imagery (see the video below for an example of applied 2D pose estimation). Pose estimation finds persons in the video and estimates where several of there joints are. With this information a skeleton that moves just like the person can be built up. Using this extracted motion at the base, we could build up an entire new scene using 3D modelling software. We use Blender for this task, as it is a free and open-source alternative that is entirely programmable using a Python API. A virtual human model would be imported into the 3D scene and made to move just like our extracted skeleton. We use the SMPL body model, which is learned from many real human 3D body scans, for this.
An additional advantage of this approach versus just repainting the original video is that all environment variables are fully and easily under our control. Body shape, clothing, lighting, camera angle and background images can all be automatically randomised, which will make our dataset more diverse and the models trained on it invariant to these redundant variables.
An example of 2D pose estimation on video.
After constructing the scene by placing the human models in it, making them move according to the extracted motion and randomising the environment variables, the entire thing needs to be rendered into a video. This video, which is called a synthetic video in literature, can now be used as training data by our deep learning model. Which environment variable randomisations or scene construction techniques have most impact on performance is of course subject of the experimentation and analysis phase that follows after the model has been trained. Also, in order to synthesise datasets of a size that is actually useful for deep learning, this whole process needs to be automated and performant.
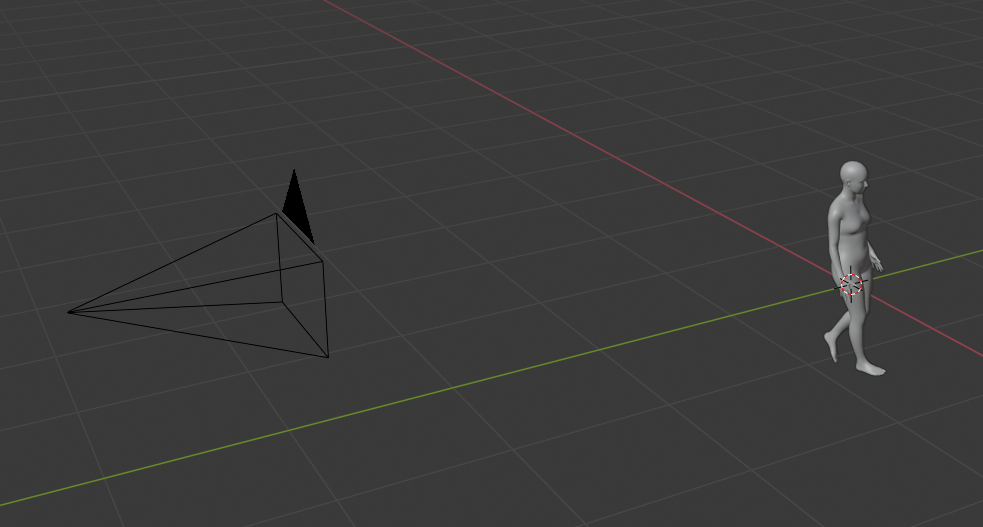
Constructing the scene for a synthetic video using 3D modelling software. A virtual camera can be seen to the left and a human body model executing a walking motion can be seen on the right.
There already are examples of synthetic datasets centred around humans out there. The SURREAL dataset is built using motion-capture data and also uses Blender to render synthetic humans. Along with a natural looking video (on the left), the authors also rendered a depth-map (visualised below) and body part segmentation (in the middle). All this information is of course known because of the 3D human body model used in Blender. These various 'views' of the same video could be used as the supervision signal for the training of a neural net-based body part segmentation estimator or human body depth estimator. Note that the natural video (on the left) does not seem totally natural to us, as the people are not realistically placed in the scene at all. However, it turns out that these inaccuracies are not relevant for the training of e.g. a depth estimator that should only focus on the human in the scene anyway. As long as the background is somewhat representative for expected background (in terms of colours, objects, shapes, etc), other constraints can be loosened. This is an enormous advantage as the authors could thus use just a plain 2D image as the background instead of creating a full 3D scene to place the synthetic human in.
Demo video showing the SURREAL dataset.
At Oddity.ai we apply state-of-the-art AI research to practice. We love to pioneer creative solutions to the challenges this brings with it. We are currently researching the use of synthetic videos as a main source of training data to strengthen our products capabilities as well as increase our independence of privacy-invading data collection practices. This blogpost was an introduction to our work but shoot us a message if you would like to know more.



